Une IA open source, capable de rivaliser avec les meilleurs modèles, entraînée pour seulement quelques millions d’euros ? C’est la révolution Moonshot AI : une prouesse qui balaie les scénarios catastrophes sur le coût énergétique de l’intelligence artificielle.
La start-up chinoise Moonshot AI, soutenue par Alibaba, vient de dévoiler Kimi K2 Thinking, son modèle de langage qui ne se contente pas de répondre, mais qui réfléchit et agit en exécutant de 200 à 300 appels d’outils séquentiellement, grâce à un raisonnement adaptatif et à long terme. Tel un ingénieur, il peut enchaîner les cycles de réflexion, de recherche, de navigation Internet, de développement — en boucle — jusqu’à trouver la solution à un problème complexe.
Comme la plupart des solutions d’IA chinoises, Kimi K2 Thinking est proposé en open source, ce qui va permettre aux autres acteurs de s’en inspirer et de progresser à leur tour. Un cycle vertueux de développement et de partage qui fait l’excellence et la fertilité de l’IA chinoise et que pratiquement aucune société américaine n’applique, sinon sur de petits modèles parfois destinés à faire de la communication plutôt qu’a un usage réel.
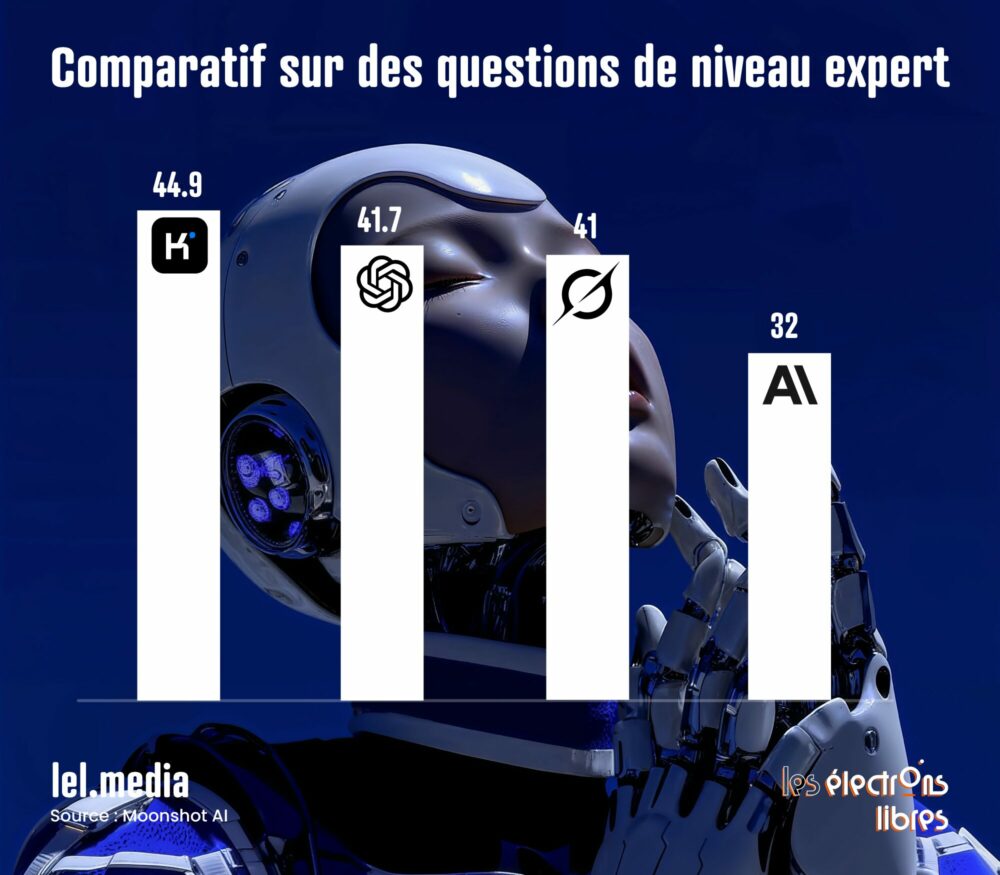
Ici, le modèle compte 1 000 milliards de paramètres : il rivalise donc en taille avec les plus grands opus des géants américains OpenAI, Google et Anthropic. Mais si la taille est une métrique, la performance en est une autre — et c’est là que Kimi K2 Thinking fait fort, en battant assez largement ses concurrents payants dans de nombreux benchmarks de raisonnement, notamment ceux qui n’impliquent pas d’étapes de programmation.
Mais ce n’est pas tout. Moonshot AI, loin des élucubrations actuelles sur les gigadatacenters pour l’entraînement de l’IA, qui consommeraient l’équivalent de la production d’une tranche complète de centrale nucléaire (la France en possède 56), annonce un coût d’entraînement record de 4,6 millions de dollars, contre des sommes des dizaines de fois plus importantes chez ses concurrents américains. Ce chiffre ne concerne que la puissance de calcul nécessaire pour entraîner le modèle, pas les salaires des ingénieurs, ni la collecte de données ou les autres frais de développement.
Cette prouesse est obtenue grâce à une astuce intelligente : Kimi K2 Thinking est entrainé à partir de son petit frère Kimi K2 (Instruct – modèle sans raisonnement) avec une précision ultra-réduite (QAT 4 bits), ce qui divise, sans perte notable de qualité, jusqu’à quatre fois la mémoire et les calculs requis. De plus, il n’active à chaque utilisation que quelques experts de 32 de ses 1 000 milliards de paramètres (architecture dite Mixture of Experts (MoE)). C’est le premier modèle de raisonnement à utiliser le QAT et le MoE, ce qui le place aussi premier à offrir un coût d’inférence aussi compétitif avec un usage plus rapide.
Puisqu’il est gratuit, combien cela vous coûterait-il de faire tourner cet ingénieur maison 24/7 ? Le ticket d’entrée, qui ne cesse de baisser, est d’environ 200 000 euros pour le serveur capable de s’y mettre. La compétition avec l’humain se rapproche.